
Neural Architecture Search: A Survey
Published:
Elsken, Thomas, Jan Hendrik Metzen, and Frank Hutter. “Neural architecture search: A survey.” The Journal of Machine Learning Research 20.1 (2019): 1997-2017.
1. Purpose
Currently, neural network architectures have to be manually developed by experts → time-consuming and error-prone.
2. Outcome
Proposed three major components: search space, search strategy, and performance estimation strategy.
3. Major components
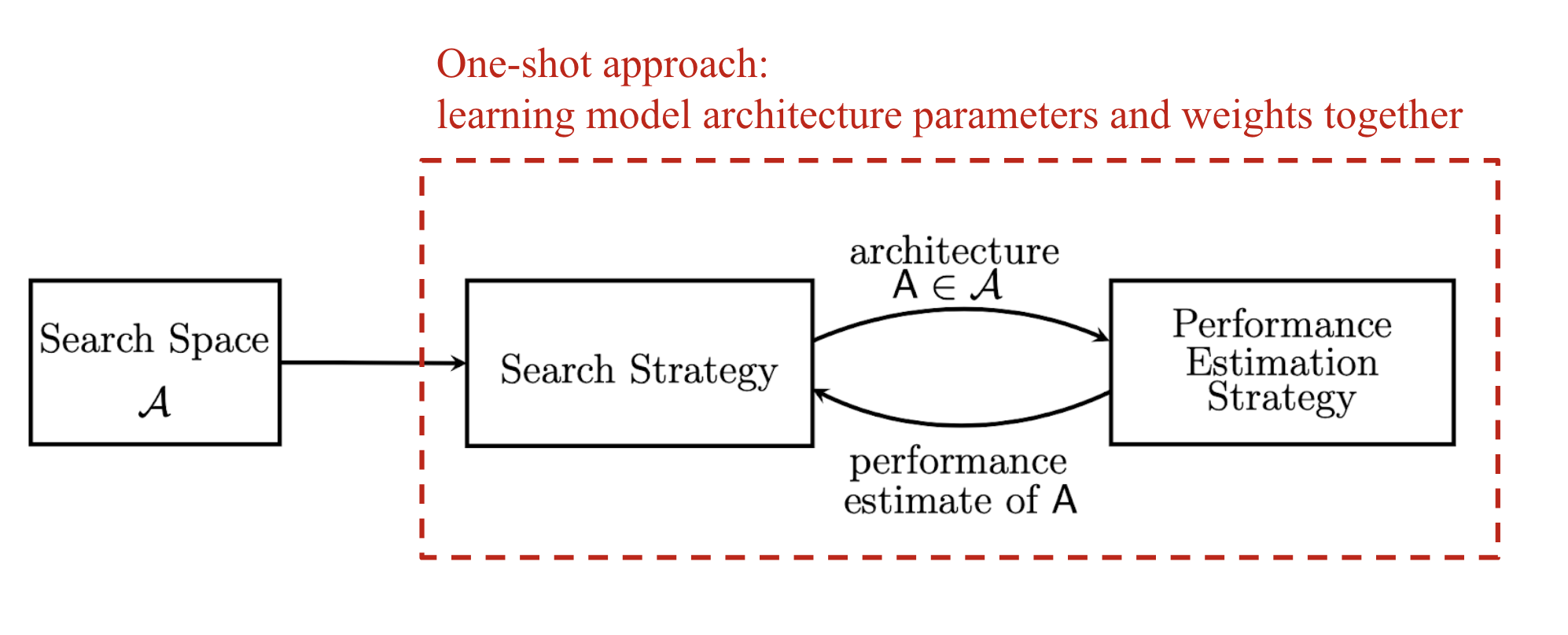
- Search Space
- Define a set of modules (operations in Lil’Log) and how they connect with each other to form a valid architecture.
- Cons: human bias → hard to find novel architectures.
- Search Strategy
- Use search algorithm to explore the search space.
- Reinforcement learning (Zoph et al. 2017), evolutionary algorithms, and gradient-based method (DARTS) are commonly used as the search strategy.
- Search strategy samples a population of neural network architecture candidates (hyper-network/super-net), which receive subnets’ performance metrics as rewards/evaluation to optimize and generate higher-performance architecture candidates.
- Performance Estimation Strategy
- Evaluating process could be very expensive and limited ⇒ new methods solve the problems.
3.1 Search Space
Chain-structured networks (Sequential-layer networks) - Zoph et al. 2017
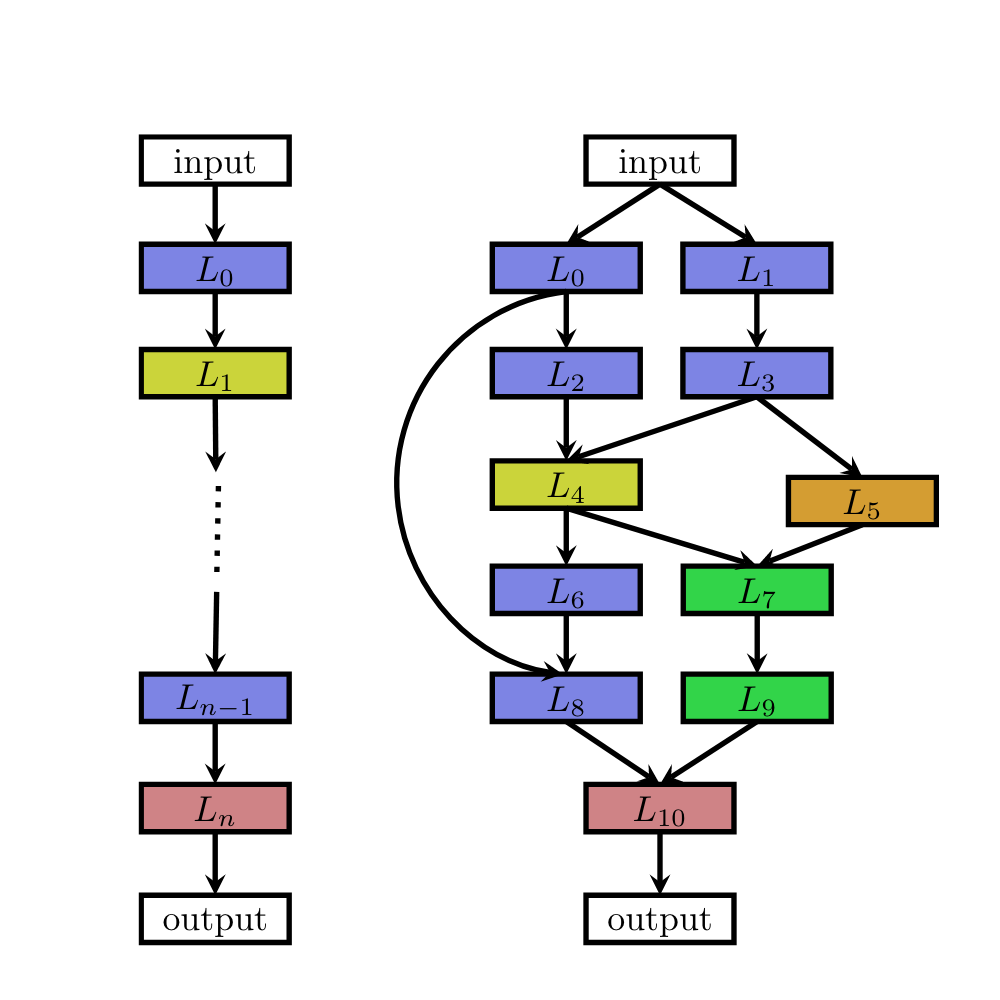
- parametrized by:
- the (maximum) number of layers $n$ (possibly unbounded)
- the type of operation every layer executes
- hyper-parameters associated (conditioned on 2.) with the operation
- pros: powerful and flexible.
- cons: computing resource consuming - 800 GPUs in parallel for 28 days to train the CIFAR-10…
- parametrized by:
Cell/Block-based representation - Zoph et al. 2018
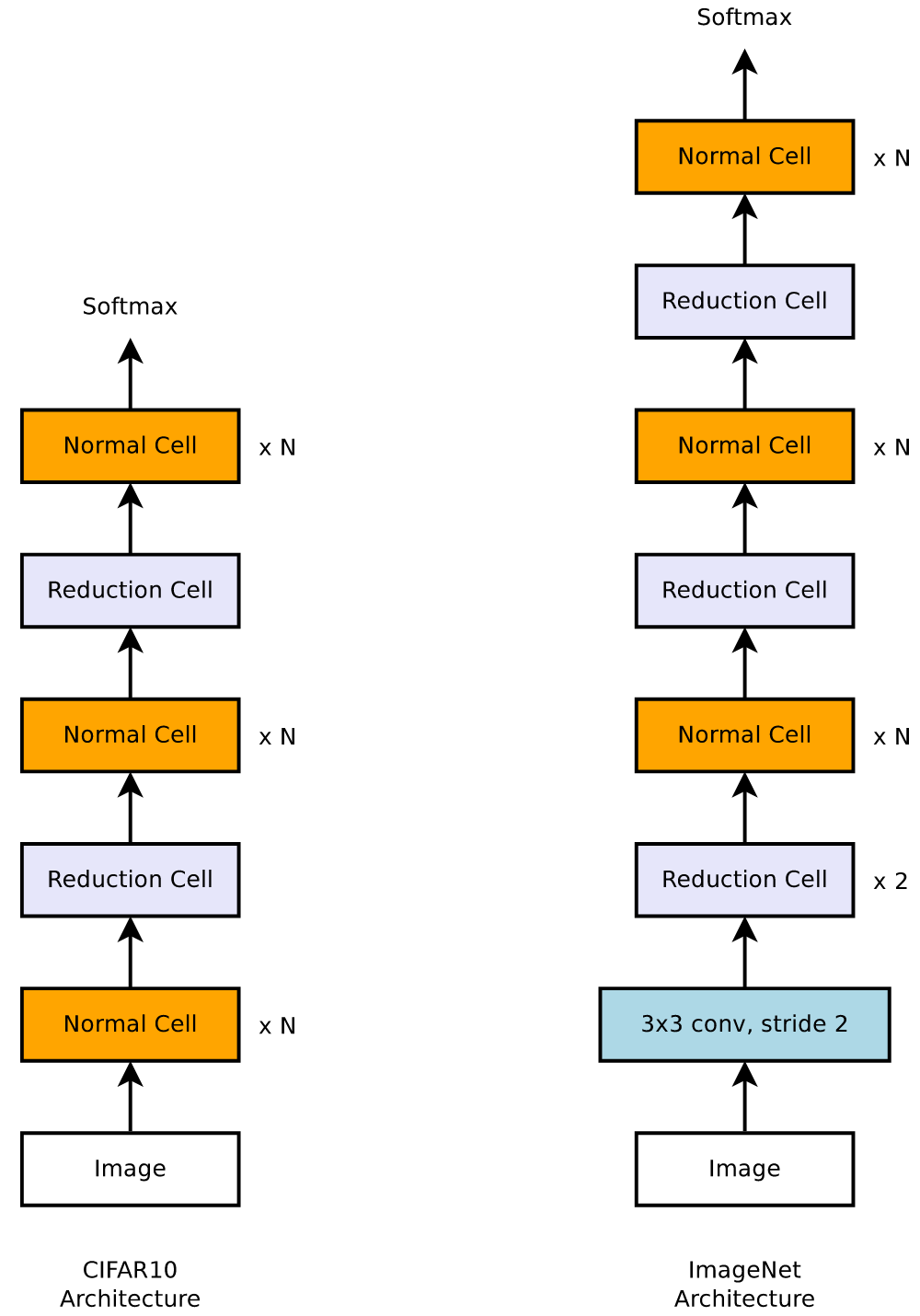
Search for cells or blocks instead of the whole architecture.
For easily build scalable architecture:
- Normal cell: input and output feature maps have the same dimension.
- Reduction cell: height and width of output feature map $\div 2$.
- ScheduledDropPath: each path in the cell is dropped out with a probability that is linearly increased over the course of training. Rather than dropping stochastically → makes the evolution youthful.
- on CIFAR-10 - SOTA on error rate.
- Easier transferability, on ImageNet - SOTA on accuracy and 9B fewer FLOPS than human-designed models.
- 450 GPUs for 3-4 days…
- Macro architecture (Hierarchical structure)
- macro-architecture: how many cells shall be used and how should they be connected to build the actual model
- micro-architecture: the structure of the cells
- both the macro-architecture and the micro-architecture should be optimized jointly instead of
solely optimizing the micro-architecture; otherwise, one may easily end up having to do manual macro-architecture engineering after finding a well-performing cell.
3.2 Search Strategy
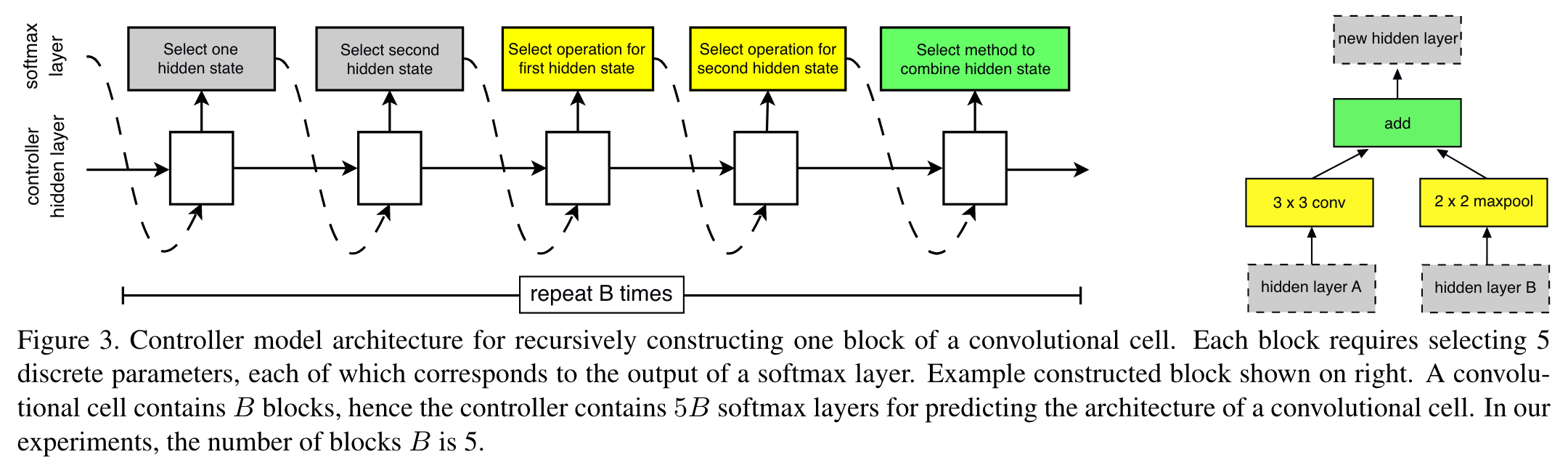
Evolutionary Algorithms (Neuro-evolutionary) - Real et al. 2019

AmoebaNet modified the tournament selection to favor younger genotypes and always discard the oldest models within each cycle. Such an approach, named aging evolution, allows AmoebaNet to cover and explore more search space, rather than to narrow down on good performance models too early.
- Initialize the population
- Pick $S$ workers at random
- Select best as parent
- Copy-mutate parent as child
- Train and evaluate the child
- Kill the oldest
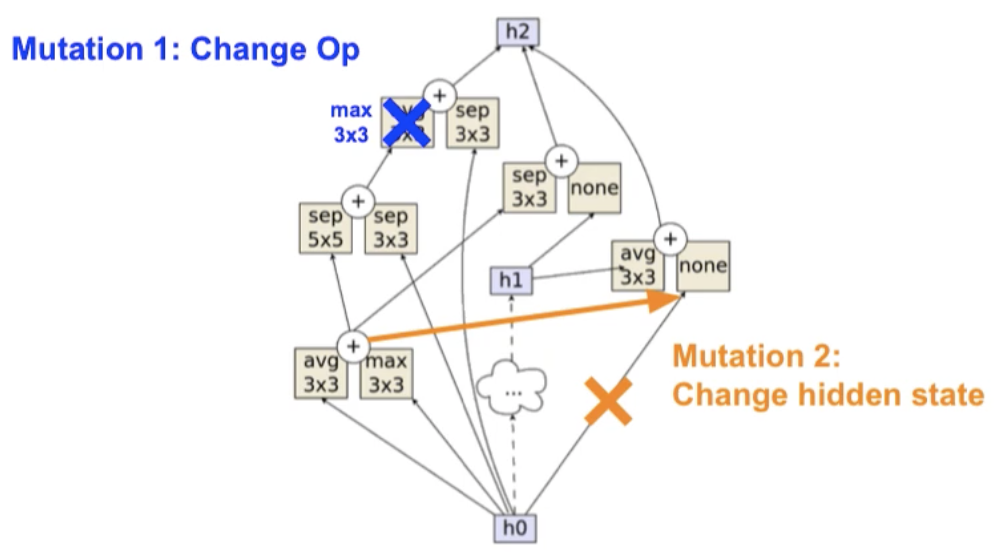
- Mutation (Real et al. 2019)
- Change Op (operation)
- Replace hidden state
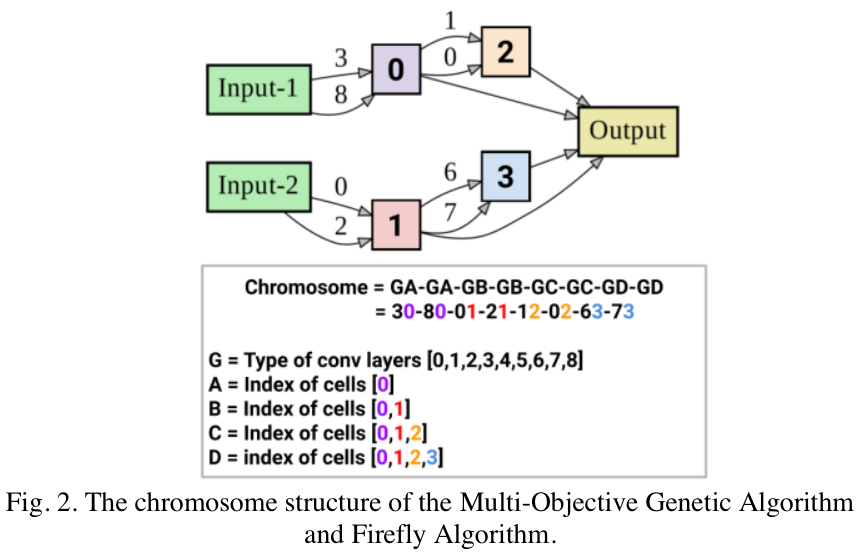
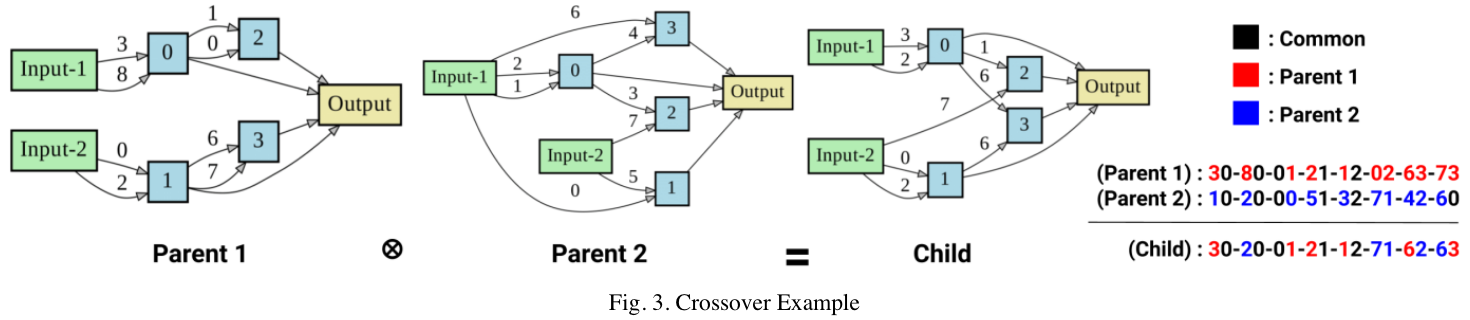
Crossover (Lin Xu et al. 2021)
Op(G)-Idx(A, B, C, D) [G-A]*2[G-B]*2[G-C]*2[G-D]*2 G=[0, 1, 2, 3, 4, 5, 6, 7, 8] A=[0] B=[0, 1] C=[0, 1, 2] D=[0, 1, 2, 3]eg. P2:
G={1,2,0,5,3,7,4,6}, A={0, 0}, B={0, 1}, C={2, 1}, D={2, 0}
3.3 Performance Estimation Strategy (Evaluation Strategy)
- Training from scratch
- the simplest way
- tremendous computational demands
- Proxy training
- fewer data/epochs; downscaled data/models (Zoph 2018)
- lower fidelity → estimation bias → stably rank different architectures
- Learning curve extrapolation
- reduce training time by extrapolate curve performance
- large search space + few estimations → good predictions → speed up search process
- Weight/network morphisms inheritance - pre-training, warm-started (Real 2017)
- One-shot models
- training a single model is enough for emulating any child model in the search space
- extend the idea of weight sharing and further combines the learning of architecture generation together with weight parameters
- treat child architectures as different sub-graphs of a supergraph with shared weights between common edges in the supergraph
- Parameter sharing (Pham et al. 2018)
- Efficient Architecture Search (EAS) (Cai 2017)
- employ RL agent as meta-controller
- grow network depth or layer width with function-preserving transformations
- reuse previous networks for further exploration and save computational cost
- Net2WiderNet allows to replace a layer with a wider layer, meaning more units for fully-connected layers, or more filters for convolutional layers, while preserving the functionality.
- Net2DeeperNet allows to insert a new layer that is initialized as adding an identity mapping between two layers so as to preserve the functionality.
- Efficient Neural Architecture Search via Parameter Sharing (Pham 2018)
- a meta-controller discovers architectures by searching sub-computational-graphs
- the controller is trained with policy gradient to select subgraphs → max reward (RL)
- the model corresponding to the subgraph → min canonical cross entropy loss (DL)
- parameters sharing → 1,000$\times$ cheaper than original NAS methods
- experiment 1: Penn TreeBank → SOTA without post-training
- experiment 2: CIFAR-10 → on a par with NASNet (Zoph, 2018)
- Efficient Architecture Search (EAS) (Cai 2017)